Research Overview #
|
# Visual Recognition The VCL Lab specializes in visual recognition for image and video understanding. Our research covers a wide range of visual recognition tasks, including image classification, object detection, and segmentation. In particular, we focus on face recognition, scene text recognition, object detection, semantic and instance segmentation, and video action recognition. Moving forward, we aim to expand our research to encompass various other visual recognition challenges. 
Keyword: Face Recognition, Action Recognition, Object Detection, Segmentation
# Learning for Visual Recognition Our lab explores machine learning and deep learning for visual recognition. In addition to traditional learning paradigms such as supervised learning, unsupervised learning, and reinforcement learning, we actively investigate cutting-edge approaches, including self-supervised learning and multimodal learning. Furthermore, we work on memory networks and transformer-based neural architectures to develop optimal learning models for visual recognition tasks. 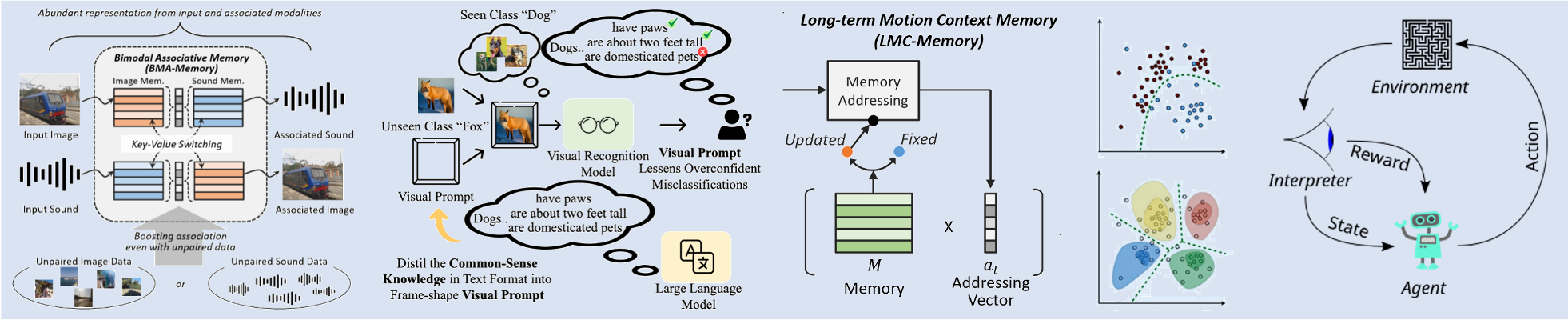
Keyword: Self-supervised Learning, Multimodal Learning, Attention, RL
# Reliability & Generalizability in Computer Vision To improve stability and generalization capability in real-world environments, our lab focuses on analyzing the model’s learning competency and developing advanced learning techniques. For example, we study competency-aware machine learning algorithms. Additionally, we explore ways to enhance generalization capability by leveraging large language models (LLMs), large multimodal models (LMMs), and mixture-of-experts (MoE) architectures to build more robust and adaptive vision systems. 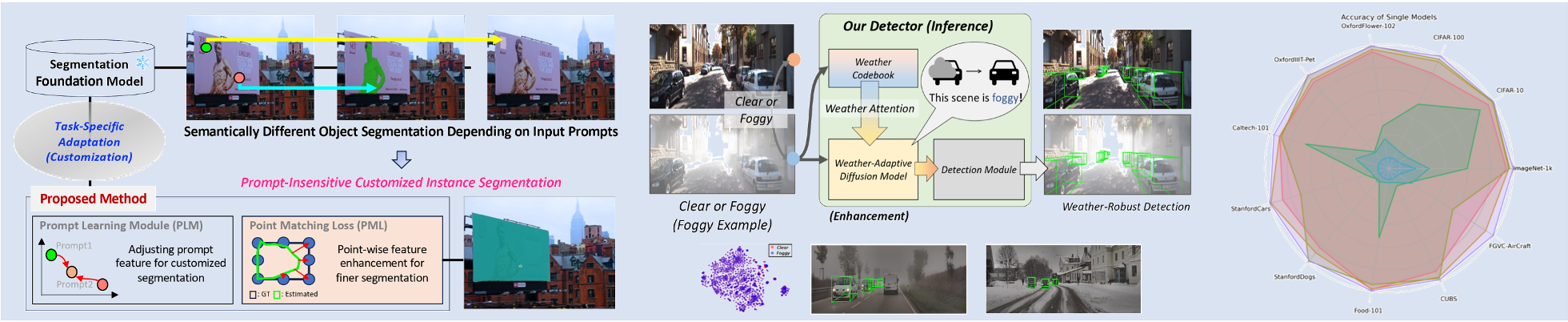
Keyword: Competency-aware Machine Learning, Prompt Learning, LLM/LMM, MoE
# Real-World Vision Applications and On-Device AI Our lab is dedicated to developing vision-based applications that solve real-world problems using advanced visual recognition technologies. Recently, we have developed and deployed privacy-preserving facial analysis, automated outdoor advertisement analysis, and illegal banner classification systems, while also expanding our research toward on-device AI for efficient and real-time visual intelligence on edge devices. Moving forward, we aim to extend our research to additional application domains, such as CCTV-based event detection and anomaly detection in public surveillance. 
Keyword: Event Detection, Anomaly Detection, On-Device AI
|
Research Projects #
Ongoing Projects
|